

K-Means 이론과 고찰 :
- 이미지의 픽셀 분포를 수학적 계산하여 세그멘테이션 분류를 할 수 있다.
- 그야말로 수학적인 알고리즘으로 픽셀을 분류한다.(머신러닝의 훈련과정은 없다. 다만 범주로 나누고자 하면, 비지도 학습 부분이라고 한다.)
- 클러스터 그룹을 나누는 과정은 거리 기반의 그룹 간 비유사도 (dissimilarity)와 같은 비용 함수 (cost function)을 최소화하는 방식으로 이루어진다(출처 : 위키피디아)
- (위키피디아에 자세한 설명있음) 한계점으로, 각 클러스터의 초기 중심값 및 유저가 설정하는 클러스터 개수에 의존성이 높으며 클러스터를 잘못 분류할 수 있는 가능성이 다소 높다.
- 하지만, 이미지를 분류하는 알고리즘 중에 가장 간단하고 빠르게 구현해볼 수 있는 장점이 있어서 이미지 세그멘테이션을 공부하는 소스로 좋은 것 같다.
k-평균 알고리즘 - 위키백과, 우리 모두의 백과사전
k-평균 알고리즘(K-means clustering algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 이 알고리즘은 자율 학습의
ko.wikipedia.org
참고한 블로그
Image Segmentation | Types Of Image Segmentation
Image segmentation tutorial to learn about types of image segmentation and its techniques. A step by step guide for how to implement them in Python.
www.analyticsvidhya.com
데모 및 사용법(code@kaggle)
(각종 라이브러리 import는 생략함. 상세 캐글 노트북)
*이미지 읽기 및 shape 변경
# make pixel values from 0 to 1
pic = plt.imread("../input/imgfile/1.jpeg")/255
# change img shape.
pic_1d = pic.reshape(pic.shape[0]*pic.shape[1], pic.shape[2]) # shape[2] is the number of channel.

*K-Means 분류기 적용하기
(공식문서)
sklearn.cluster.KMeans
Examples using sklearn.cluster.KMeans: Release Highlights for scikit-learn 0.23 Release Highlights for scikit-learn 0.23, Demonstration of k-means assumptions Demonstration of k-means assumptions, ...
scikit-learn.org
# import kmeans library
from sklearn.cluster import KMeans
kmean = KMeans(n_clusters=5, random_state=0).fit(pic_1d)
KMeans 라이브러리 적용으로, 다음과 같은 데이터를 가져올 수 있다.
- labels_ : 각 픽셀의 클러스터 레이블 값(사용한 데모에서는 n_clusters=5 이기 때문에 0~4 중에 하나의 레이블이 각 픽셀에 할당되어진다.)
- cluster_centers_ : 알고리즘 계산으로 결정된 각 클러스터 영역의 중심 좌표값
*출력된 데이터를 이미지에 적용 및 reshape 하기
# apply kmean attribues and ready for showing.
pic2show = kmean.cluster_centers_[kmean.labels_]
# change shape of matrix with original img shape.
clusterPic = pic2show.reshape(pic.shape[0],pic.shape[1],pic.shape[2])5개의 클러스터 그룹으로 분류된 이미지를 확인할 수 있다.

*레이블 데이터의 히스토그램 : Kmean의 필드 값인 labels_ 의 분포를 확인.
import seaborn as sns
sns.histplot(data=kmean.labels_)
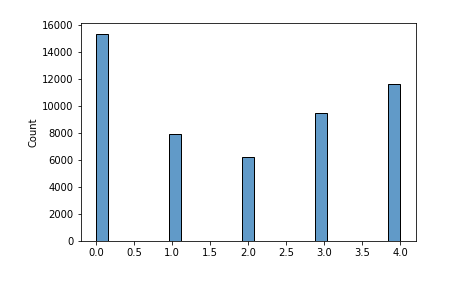
다음엔 조금 더 고난도의 세그멘테이션에 도전 !
'[ STUDY ]' 카테고리의 다른 글
| [ LINUX ] 우분투. 터미널에서 사용했던 쉘 관련 커맨드 모음 (0) | 2022.07.21 |
|---|---|
| [ C++ ] Binary search 구현해보기. (0) | 2022.02.23 |
| C++ vector 타입과 조금 다른 C# List 타입 변수의 사용. (0) | 2022.02.13 |
| [ 깃헙 사용법 ] 깃 커맨드로 특정 파일의 업데이트(반영) 무시하는 방법. (0) | 2021.06.19 |
| [ C 언어 ] 실무에서 막혔던 문자열 관련 유용한 내용.(함수만들기) (0) | 2021.04.04 |