노마드코더에서 제공하는 무료 강의 중 파이썬을 이용한 웹스크레이핑 강의가 있습니다.
이 강의를 통해 구인정보를 긁어오는 방법을 배우고, 배움을 이어나가기 위해 다른 웹사이트에도 같은 구조로 적용을 해봤습니다.
참고로, 노마드코더에서 진행한 구인정보 웹사이트는 인디드(Indeed)와 스택오버플로우(Stackoverflow) 입니다.
또 다른 스크레이핑 방법 : Chromedriver를 이용하는 방법(beomi 님 블로그)
스크래핑 웹사이트
(회사에서 벤치마크 관련 자료 조사 차 기사를 뒤져볼 일이 있어서 해당 웹사이트를 긁어보기로 했음.)
- 토요 타이어 : https://www.toyotires.co.jp/press/
- 요코하마 타이어 : https://www.y-yokohama.com/release/
스크레이핑에 사용된 라이브러리는 다음과 같습니다.
import requests
from bs4 import BeautifulSoup
일단, 스크레이핑 하고자 하는 웹사이트의 접근(?) 이 가능한지부터 확인한다.
http status code를 다음과 같이 확인
#toyo.py
import requests
from bs4 import BeautifulSoup
URL = 'https://www.toyotires.co.jp'
results = requests.get('https://www.toyotires.co.jp')
print(results)
프린트 값이 200 이 나오면 아무 이상 없이 웹사이트 접근이 가능한 것, 경우에 따라서는 4xx 번호가 나올 때도 있는데,
해당 경우에는 보안(?) 구조상 일반적인 방법으로는 접근이 불가능한 것 같다.
페이지 인디케이터 검색
페이지를 갱신해가면서 데이터를 가져오는 과정이 필요하므로, page number, year number 등의 정보를 찾아온다.
구인광고의 경우, 한 페이지에 특정 개수 결과를 복수 페이지에 걸쳐서 표시해주었다.
하지만, 찾고자 하는 데이터, 웹페이지에 따라 그 양식이 다를 수 있기 때문에 그에 맞게 바꿔줄 필요가 있다.
또한, 이런 데이터를 인디케이터로써 활용한다.
토요 타이어는 우측의 2019年,2018年,2017年 등 연도별로 기사 내용을 긁어오기로 한다.

#toyo.py
def get_year_list():
years = []
results = requests.get(f'{URL}/press/2019')
soup = BeautifulSoup(results.text, 'html.parser')
year_lump_data = soup.find('div', {'id': 'block-views-block-press-year-list-block-1'})
list_year = year_lump_data.find_all('a')
for year in list_year:
year_num = year.get('href')
year_num = year_num.split('/')[-1]
years.append(int(year_num))
# returns years that type of list(int)
return years
그리고, 아래 그림과 같이 한 연도에 대한 표시 기사가 제한되어 있어 다음 기사를 보기 위한 '더보기(もっと見る)' 버튼이 위치하고 있는데, 한 연도의 전체 기사를 스크레이핑 할 때 '더보기' 버튼을 이용해서 전체 기사를 긁어온다. 버튼에 대한 내용은 후반부에 자세히 설명하겠다.
반면 요코하마 타이어의 경우는 다음과 같다.
토요 타이어 페이지와 비교했을 때 연도 표시 내비게이터가 없다는 점 외에는 비슷하다.
우측 하단에 '오래된 기사(古い記事)'를 누르면 다음 페이지의 내용을 계속 보여준다. next button 개념이므로, 어떤 정보를 가지고 있는지는 우클릭-검사를 통해서 인디케이터 내용을 뽑아내면 된다.
#yoko.py
URL = 'https://www.y-yokohama.com/release/'
def last_page():
num = 0
last_page = 0
print('Trying find last page number..')
while(1):
results = requests.get(f'{URL}?sp={num}&lang=ja')
soup = BeautifulSoup(results.content,'html.parser')
next_button_section = soup.find('div',class_='sec-contents--lv3')
next_button = next_button_section.find_all('a')
if (num != 0 and len(next_button) == 1):
break
else:
num +=20
last_page = num
print(f'last page number is {last_page}')
return last_page
위 코드에서는 페이지를 다음으로 진행시킴으로 인해, 하단부에 생기는 버튼의 개수를 조건문으로 체크하고 마지막 페이지를 리턴하도록 작성했다.
페이지를 다음으로 넘겼을 때 현재 페이지 기준으로 앞 뒤 페이지가 있으면, 좌(新しい記事:새로운 기사), 우(古い記事:오래된 기사) 버튼이 각각 생기게 되고, 마지막 페이지로 도착하면 좌(新しい記事:새로운기사) 한 개의 버튼만 표시되게 된다.
URL에 표시된 'sp=xxx' 정보로 페이지 정보를 확인할 수 있다.
페이지를 넘길 때마다 매번 requests.get(URL)을 해주도록 함수를 만들어 사용하는데, 매번 페이지마다 풀 패스로 접속해서 상태를 확인하는 구조이기 때문에 더 나은 방법이 있는지 생각하게 되는 부분이기도 하다.
원(One) 페이지 데이터(토요 타이어 웹사이트 기준으로만 설명함)
각 연도별 기사 내용이 출력되는 구조이므로, 연도수(ex: 2019, 2018..)를 함수의 인자로 받아 다음과 같은 메타데이터를 추출 한도록 셋팅함.
- Category : 기사 분류 타이틀(타이어 사업, 일반, 이벤트 및 그 외, 경영, CSR 환경 등)
- Upload date : 기사 게시 날짜
- Title : 기사 제목
- Link URL : 기사 페이지 링크
먼저, 한 페이지(2019년도)에 대해서 메타데이터 내용을 추출한다.
인자로 선언된 'html' 은 한 페이지 전체를 BeautifulSoup으로 파싱 해준 텍스트 데이터가 된다.
#toyo.py
def get_article_info(html):
# filtering by categorical classification of the article.
# _cate02 is article that is for tire business
# label is class name for categorical classification
cate = html.find('span', {'class': '_cate02'})
if cate != None:
cate = cate.get_text(strip=True)
date = html.find('div', {'class': 'date-cell'}).get_text(strip=True)
title = html.find('div', {'class': 'ttl-cell'}).find('a').get_text(strip=True)
link = html.find('div', {'class': 'ttl-cell'}).find('a').get('href')
return {
'Category': cate,
'Upload date': date,
'Title': title,
'link': f'{URL}{link}'
}
else:
return None
'타이어 사업' 카테고리를 가지는 기사만 추출하기 위해, '타이어 사업' 카테고리 클래스를 나타내는 '_cate02'로 필터링 작업을 넣어줬다.
#위 내용 중 일부
cate = html.find('span', {'class': '_cate02'})
if cate != None:
조건문을 통과한 기사에 대해서만, 날짜/제목/기사 링크 데이터를 반환해 주면 끝난다.
복수 페이지 데이터
원 페이지 데이터를 포맷으로, 여러 페이지에 적용시킨다.
다시 말하면, '더보기' 또는 연도가 바뀔 때마다 새로운 기사가 갱신되는 개념이기 때문에 똑같이 정해진 포맷으로 추출한다고 생각하면 이해하기 쉬울 것 같다.
#toyo.py
def get_articles(list_of_years):
articles = []
for year in list_of_years:
for page in range(last_page(year)):
print(f'Scraping {year} year, {page+1} page..')
results = requests.get(f'{URL}/press/{year}?page={page}')
soup = BeautifulSoup(results.text, 'html.parser')
articles_raw = soup.find_all('div', {'class': 'con'})
for article in articles_raw:
article_content = get_article_info(article)
# it needs exclude None data
if article_content != None:
articles.append(article_content)
else:
None
return articles
연도 데이터를 리스트 형태의 인자로 받는다.
리스트 인자를 받은 후, URL에 문자열로 할당해서 페이지를 차례로 로딩한다.
그리고, 한 연도의 마지막 페이지를 검색 후, 1페이지부터 html 파싱 데이터를 던져주고, 원하는 포맷으로 추출하는 함수를 적용한다.
끝으로, 추출된 데이터를 리스트 요소로 추가해주고 추출된 데이터를 리스트 형태로 리턴 해준다.
이런 구조로 제일 상위(?)의 함수 구조는 다음과 같이 셋팅할 수 있다.(이 함수를 메인에서 임포트 하여 사용한다.)
#toyo.py
def articles():
print('Scrapping Start : TOYO COMPANY')
years = get_year_list()
articles_results = get_articles(years)
print(f'Number of TOYO Articles : {len(articles_results)}')
return articles_results
데이터 저장 및 출력
사용한 라이브러리는 csv이다.
#save.py
import csv
위에서 다음과 같은 형태로 데이터를 구성했다. CSV로 저장하기 위해 미리 정리해둔 셈이다.
#toyo.py 위의 코드 중 일부
return {
'Category': cate,
'Upload date': date,
'Title': title,
'link': f'{URL}{link}'
}
CSV 라이브러리에 대한 자세한 내용은 다음의 도큐먼트를 참고하면 될 것 같다.(https://docs.python.org/2/library/csv.html)
위의 형태로 저장된 리스트(사전형 데이터 덩어리를 요소로 가지는 리스트)를 인자로 받고, 사전형 데이터의 Value값을 저장한다.
#save.py
def save_to_csv(articles):
f = open('data.csv', 'w')
datafile = csv.writer(f)
datafile.writerow(['Category','Upload date','Title','link'])
for article in articles:
datafile.writerow(list(article.values()))
return
main.py 파일 구성
#main.py
from toyo import articles as toyo_articles
from yoko import articles as yoko_articles
from save import save_to_csv
toyo = toyo_articles()
yoko = yoko_articles()
articles = toyo + yoko
save_to_csv(articles)
특별한 건 없다. 이렇게 구성하고 python main.py (enter) 하면 스크레이핑이 시작된다.
몰랐던 내용은, 'toyo + yoko' 이 연산으로 모든 데이터를 누적해서 합칠 수 있었던 점이다. 간단하고 효과적이라고 생각된다.
이렇게 해서, data.csv. 파일이 생성되는 것을 확인할 수 있다.
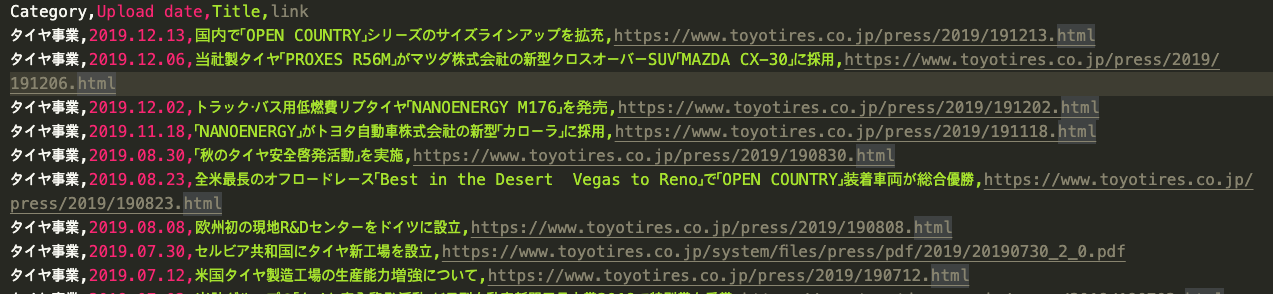
끝.
'[ Python ]' 카테고리의 다른 글
| [Python] numpy.ndarray.T 사용 해보기. (0) | 2023.05.02 |
|---|---|
| 코랩(colab) 에서 캐글(kaggle) 데이터셋 이용 하는 방법 (0) | 2023.04.09 |
| [Python] Run-Length Encoding 사용하여 이미지 픽셀 라벨링 하기. (0) | 2023.02.12 |


